
강화학습을 게임 봇 만들기 (1)
배경
- 개요
- PVP 게임에서 유저 대신 봇으로 대체하는 경우가 있음
- 매칭할 유저가 적거나
- 유저와 매칭할 실력이 안되는 초보자를 케어하기 위해
- 이러한 경우 봇 플레이가 단조로워 아쉬웠음
- 일반 유저와 비교하여 실력 차이가 크게 나고, 단일 난이도로 구성
- 미션이 주어진 경우에는 협동해서 플레이하기가 어려움
- 특정 지역으로 같이 이동하는데 전투 지역을 벗어나 있음
- 전투 시 도움이 필요할 때 도와주지 않음
- FPS 게임에서는 이따금씩 특정 구역에서 가만히 서성이고 있다던가
- 은폐/엄폐 없이 전투를 진행
- 위 같은 점들 때문에 매치에 봇이 포함되면 플레이 긴장도가 크게 낮아짐
- PVP 게임에서 유저 대신 봇으로 대체하는 경우가 있음
- 목적
- 기존에 어떻게 봇을 만들고 왜 만들기 어려운 지 파악
- 다른 방식을 통해 위 봇 문제점을 해결할 수 있을지 테스트
기존 시스템 이해
기존 봇을 만들 때 자주 사용되는 Behavior Tree에 대한 이해
- Behavior Tree
- 우선 순위와 트리 구조를 이용해 인공지능을 설계하는 방법
- 모듈화가 자유로워 확장이 쉬움
- Halo2에서 사용되고 GDC 2005년 소개
- 구성 요소
- Root, Composite, Action
- 항상 왼쪽에 있는 노드에 우선 순위를 부여

Behavior Tree 예시
- Composite 노드에서 다수의 행동을 컨트롤 함
- Selector: 여러 행동 중 하나의 행동 선택
- Sequence: 여러 행동을 순차적으로 수행
- Parallel: 여러 행동을 함께 수행
- Composite 노드 내 부가 요소
- Decorator: 노드가 실행되는 조건(조건문)(파란색)
- Service: 노드가 활성화될 때 실행되는 부가 명령
- Abort: Decorator 조건에 부합하면 노드 내 활동 모두 중단(빨간색)
- Black Board
- Behavior Tree에서 행동을 결정할 때 필요한 모든 정보를 저장
- 그 외로도 State Machine, GOAP(Goal Oriented Action Planning) 등을 사용
강화 학습 문제로 해결?
- 주어진 환경(Environment)과 상호 작용하여 봇(Agent)이 최종 목표를 달성할 수 있도록 학습하는 문제
- 상호 작용이란 환경에 대한 관찰 정보(State, Observation)와 이에 대한 봇의 행동(Action) 그리고 이에 따른 보상(Reward)
- 특정 상황에서 특정 행동을 하도록 설정하지 않음
- State, Action, Reward를 바탕으로 Agent가 어떻게 행동할 지에 대한 정책(Policy) 학습
강화 학습 구성 요소
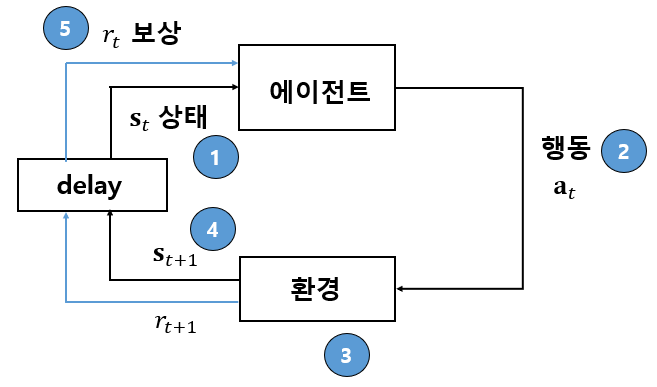
강화 학습 구성 요소
- Agent
- 봇
- Action(Actuator)
- Agent가 취할 수 있는 행동
- Environment
- 환경
- Observation
- Agent가 인식할 수 있는 환경 정보
- step
- agent가 받는 정보의 시간 단위를 step이라고 함(t로 표기)
- 각 step 별 Environment에서 state(observation)을 받고 그에 따른 action을 취함
- 하나의 게임을 Episode라 하고, Episode는 여러 step으로 이루어짐
모델을 사용한다면 이렇게 풀 수 있지 않을까?
딥러닝 모델을 사용하여 목표 지표를 최대화하는 각 상황 → 행동 매핑 함수를 만들 수 있음

강화 학습 모델 설명
강화 학습을 푸는 여러 방법이 있지만 그중에서 많이 사용되는 알고리즘을 간략하게 설명
가치 신경망 모델
- 현재 상황과 agent 행동에 대한 기대되는 보상을 예측
- 필요한 이유는 한 게임(Episode)에 대한 보상(reward)은 한번만 주어짐
- 이기거나 지거나 등
- 어떤 상황에서 어떤 행동이 해당 보상에 기여했는지 알기 어려움
- 특정 시점(step)에서의 환경(State)에 대한 보상을 모델링
정책 신경망 모델
- 현재 상황에서 각 행동에 대한 확률값을 모델링
- 각 상황에 대한 위 가치 판단 모델을 사용하여 action을 평가하고, 가치 모델이 더 높은 보상을 받을 수 있도록 action을 학습
모델 테스트
강화학습 테스트
- 간단한 문제를 설정하여 강화 학습으로 풀 수 있는 지 실험
- 기존에 관심 있었던 FPS 게임으로 먼저 테스트
- FPS에서 기본적인 기능을 강화 학습 모델로 풀 수 있는 지 개념 증명
- 기본적인 기능
- 대상 인식하기
- 현재 위치에서 인식 가능한 범위 내에 대상이 있을 때, 대상이 있는 지 확인 가능
- 대상 찾아가기
- 전체 이동 가능한 공간에서 대상이 어디 있는 지 탐험
- 대상 인식하기
- 기본적인 기능
테스트 환경 선택
- 유니티 mlagents VS 언리얼엔진 learning agent
- 언리얼엔진이 behavior tree 개발 툴을 기본적으로 제공하고 그래픽이 더 사실적이나, 강화 학습 모듈인 learning agent 관련 정보가 적음
- 그에 비해 Unity는 mlagents 관련 정보가 인터넷에 많아 Unity를 사용하기로 선택
대상 인식하기
- 현재 위치에서 대상(적)이 어느 위치에 있는 지 확인하고 인식하는 기능을 테스트
- 어떤 방식으로 Agent가 대상을 인식할 수 있는 지 파악하고 얼마나 잘 파악하는 지 확인
- 어떤 방식 → 어떤 데이터를 주었을 때
- 인식 → 대상을 맞추는 행위로 정의
Ray Cast Sensor(Observation)
- 이미지에 비해 처리할 데이터가 적기 때문에 ray cast를 Agent의 observation으로 sensor 자주 사용
- 각 ray마다 tag가 있는 object를 맞았냐 안 맞았냐 boolean값 반환

Raycast
- point A(x, y, z)에서 point B로 선을 그리는 것
- 총 쏘기(투사체 없음)에 주로 사용
- 미리 인식이 필요한 타겟 object에 tag를 붙임
- ray cast가 해당 tag에 맞으면 관련 정보를 받음
- 관련 정보로 ray cast가 맞았는 지, 맞았을 때 거리 등등을 얻을 수 있음
환경 세팅 정리
| 종류 | 변수 | 설명 |
|---|---|---|
| Observation | Target Ray Cast 6개 | - 각 Ray Cast 별 타겟이 맞았는 지 여부 - 값: 0, 1 - 거리 제한: 50 |
| Agent 현재 y축 rotation | - agent의 현재 y축 roattion 값 - 값 범위: -90 ~ 90 |
|
| Action | y축 roatation move | - agent y축으로 회전 - 값 범위: -90 ~ 90 |
| shoot | - 총 발사 | |
| Reward | target shoot | - 타겟 상자를 맞추었을 때 +1 |
| count down reward | - 매 step마다 -1/max_step - 빠르게 게임을 끝나도록 유도 |
빠른 속도 영상 예시

대상 인식
한쪽 방향으로 돌면서 상자를 잘 맞춤
일반 속도 영상

대상 인식
→ Ray Cast 사이에 있는 물체를 가끔 못 맞추지만 의도대로 동작
대상 찾아가기
맵에서 대상 찾기
- FPS에서 전투에 진입 전까지 맵을 돌아다니며 적의 위치를 파악
- 전체 맵에서 대상의 위치 정보 없이 맵을 탐험하여 대상을 찾을 수 있는 지 테스트
- 대상을 찾음 → Agent의 정해 놓은 시야 범위(사각뿔대)에 들어오는 지로 파악
- 현재 Agent 위치 정보 추가
환경 세팅 정리
| 종류 | 변수 | 설명 |
|---|---|---|
| Observation | Wall Ray Cast(6개) | 각 Ray Cast 별 벽에 맞았는 지 여부 값: 0, 1 거리 제한: 50 |
| Target Ray Cast(6개) | 각 Ray Cast 별 대상이 맞았는 지 여부 값: 0, 1 거리 제한: 50 |
|
| Agent y축 rotation | agent의 현재 y축 roattion 값 값 범위: -90 ~ 90 |
|
| Agent x,z축 position(2개) | 높이(y)값은 고정되어 있으므로 x축, z축 값만 반환 값 범위: -inf ~ inf |
|
| Action | x축 move | agent 앞, 뒤로 움직임 값 범위: -1 ~ 1 |
| y축 roatation move | agent y축으로 회전 값 범위: -90 ~ 90 |
|
| Reward | target found | 대상을 찾았을 때(사각뿔대 범위에 들어왔을 때)를 맞추었을 때 +1 |
| count down reward | 매 step마다 -1/max_step 빠르게 게임을 끝나도록 유도 |
영상 예시

찾아가기 실패
- 대상을 찾는 경우보다 못 찾는 경우가 더 잦음
- 원인을 Ray Cast의 한계로 추측
- 0, 1로만 물체/벽을 인식하기 때문에 ray cast가 맞은 지점까지의 거리를 알기 어려움
- 그렇기 때문에 agent 위치와 목표물의 위치 파악이 어려움
- 맵에서 어디를 탐색하였고 하지 않았는지 확인이 어려움
Grid Map(Observation)
| Agent 위치 | 탐험한 위치 | ||
| 탐험한 위치 |
- 롤에서 미니맵으로 현재 위치를 파악하듯이 전체 맵을 구간 나누어 위치 정보 추가
- 미탐험 지역은 0, 지나간 구간을 1, 현재 위치해 있는 곳을 2로 표시하여 전달
환경 세팅 정리
| 종류 | 변수 | 설명 |
|---|---|---|
| Observation | Grid Map(5 x 5) | 전체 맵에서 agent의 현재 위치와 탐험한 위치를 전달 값: 0, 1, 2 |
| Target Ray Cast(6개) | 각 Ray Cast 별 대상이 맞았는 지 여부 값: 0, 1 거리 제한: 30 |
|
| Wall Ray Cast(6개) | 각 Ray Cast 별 벽에 맞았는 지 여부 값: 0, 1 거리 제한: 30 |
|
| Agent y축 rotation | agent의 현재 y축 roattion 값 값 범위: -90 ~ 90 |
|
| Agent x,z축 position(2개) | 높이(y)값은 고정되어 있으므로 x축, z축 값만 반환 값 범위: -inf ~ inf |
|
| Action | x축 move | agent 앞, 뒤로 움직임 값 범위: -1 ~ 1 |
| y축 roatation move | agent y축으로 회전 값 범위: -90 ~ 90 |
|
| Reward | target found | 대상을 찾았을 때(사각뿔대 범위에 들어왔을 때)를 맞추었을 때 +1 Episode 내에서 대상을 찾을 경우 0~1 값을 받음 Episode 내에서 대상을 못 찾는 경우 -1 |
| count down reward | 매 step마다 -1/max_step 빠르게 게임을 끝나도록 유도 |
학습 결과 예시

찾아가기 성공
- Ray Cast만 사용한 경우보다 대상을 찾는 경우가 더 많아졌음
- 하지만 벽을 피하지 못하고 부딪히면서 움직이거나 대상을 찾기까지 시간이 비교적 오래 걸림
- ray cast와 마찬가지로 각 대상까지의 거리를 알기 힘들기 때문이라고 추측
- 주변 환경에 대한 인식 해상도가 높아질 필요가 있음
환경 새로 구성
- 장애물(벽)을 잘 회피하면서 대상을 찾아가도록 유도하기 위해 벽을 랜덤하게 설치
- Agent 기준으로 대상이 벽 뒤에 있을 경우 인식이 안되도록 설정
- 주변 환경을 인식할 수 있는 새로운 sensor 추가
Grid Sensor(Observation)

https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Design-Agents.md#groups-for-cooperative-scenarios
- Grid Map 대신 agent 주변을 grid로 나누어 태그에 따른 정보를 받음
- 기존 mlagents 패키지에서 제공하는 observation으로 모델에 전달하기 전에 학습된 이미지 모델로 전처리하여 전달(resnet)
어떤 sensor가 좋은 지 비교
- 어느 sensor가 효과 있는 지 비교하기 위해 동일한 환경에서 각 sensor를 사용한 모델 비교(grid map / grid sensor)
- 기존처럼 플레이 영상으로 파악하기보다는 reward 지표로 확인
- reward가 높을수록 빠른 시간 내에 대상을 찾음
- 추가로 어떤 grid map / grid sensor가 더 효과적인 지 확인하기 위해 각 모델을 따로 학습
- 240127_grid(보라): grid sensor와 grid map을 모두 사용한 모델
- 240128_grid_sensor(초록): grid sensor를 사용한 모델
- 240129_grid_map(주황): grid map을 사용한 사용한 모델
- 탐험하지 않은 구간을 얼마나 적극적으로 확인하는 파악하기 위한 지표(Grid Counts) 추가
- 1000개 step 별 평균 탐험 구간 수 지표로 확인
Reward 비교

Reward Graph
Grid Counts 비교
전체 맵에서 탐헌하는 grid 개수를 계산

Grid Counts
- Grid Sensor(초록)를 이용한 모델이 Grid Sensor + Grid Map(보라)나 Grid Map(주황)만 사용한 경우보다 reward값이 높음
- Grid Sensor + Grid Map를 모두 이용한 경우, Grid Sensor보다 탐험한 공간이 더 적음
학습 예시 영상
Grid Sensor + Grid Map 둘 다 사용한 모델

대상 찾아가기
→ 탐험한 구간을 반복해서 가지 않고, 벽을 잘 피해 다니며 대상을 찾음
Map을 사용해서 더 효율적으로 탐색
Leave a comment