
[Kakao Blind] 추석 트래픽
문제 설명
추석 트래픽
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
입력 형식
solution함수에 전달되는lines배열은 N(1 ≦ N ≦ 2,000)개의 로그 문자열로 되어 있으며, 각 로그 문자열마다 요청에 대한 응답완료시간 S와 처리시간 T가 공백으로 구분되어 있다.- 응답완료시간 S는 작년 추석인 2016년 9월 15일만 포함하여 고정 길이
2016-09-15 hh:mm:ss.sss형식으로 되어 있다. - 처리시간 T는
0.1s,0.312s,2s와 같이 최대 소수점 셋째 자리까지 기록하며 뒤에는 초 단위를 의미하는s로 끝난다. - 예를 들어, 로그 문자열
2016-09-15 03:10:33.020 0.011s은 2016년 9월 15일 오전 3시 10분 33.010초부터 2016년 9월 15일 오전 3시 10분 33.020초까지 0.011초 동안 처리된 요청을 의미한다. (처리시간은 시작시간과 끝시간을 포함) - 서버에는 타임아웃이 3초로 적용되어 있기 때문에 처리시간은 0.001 ≦ T ≦ 3.000이다.
lines배열은 응답완료시간 S를 기준으로 오름차순 정렬되어 있다.
출력 형식
solution함수에서는 로그 데이터lines배열에 대해 초당 최대 처리량을 리턴한다.
입출력 예제
예제1
- 입력: [ 2016-09-15 01:00:04.001 2.0s, 2016-09-15 01:00:07.000 2s ]
- 출력: 1
예제2
- 입력: [ 2016-09-15 01:00:04.002 2.0s, 2016-09-15 01:00:07.000 2s ]
- 출력: 2
- 설명: 처리시간은 시작시간과 끝시간을 포함하므로
첫 번째 로그는
01:00:02.003 ~ 01:00:04.002에서 2초 동안 처리되었으며, 두 번째 로그는01:00:05.001 ~ 01:00:07.000에서 2초 동안 처리된다. 따라서, 첫 번째 로그가 끝나는 시점과 두 번째 로그가 시작하는 시점의 구간인01:00:04.002 ~ 01:00:05.0011초 동안 최대 2개가 된다.
예제3
- 입력: [ 2016-09-15 20:59:57.421 0.351s, 2016-09-15 20:59:58.233 1.181s, 2016-09-15 20:59:58.299 0.8s, 2016-09-15 20:59:58.688 1.041s, 2016-09-15 20:59:59.591 1.412s, 2016-09-15 21:00:00.464 1.466s, 2016-09-15 21:00:00.741 1.581s, 2016-09-15 21:00:00.748 2.31s, 2016-09-15 21:00:00.966 0.381s, 2016-09-15 21:00:02.066 2.62s ]
- 출력: 7
- 설명: 아래 타임라인 그림에서 빨간색으로 표시된 1초 각 구간의 처리량을 구해보면
(1)은 4개,(2)는 7개,(3)는 2개임을 알 수 있다. 따라서 초당 최대 처리량은 7이 되며, 동일한 최대 처리량을 갖는 1초 구간은 여러 개 존재할 수 있으므로 이 문제에서는 구간이 아닌 개수만 출력한다.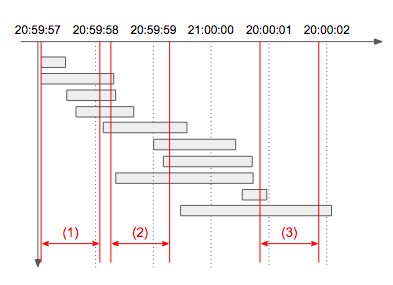
풀이
생각보다 굉장히 어려웠서 오래 걸렸다. 막상 풀고나니 방법이 간단해서 허무하다. 진작에 이렇게 풀었어야하는데…
문제에서 어려웠던 점은 매초마다의 트래픽이 아니라 임의의 1초에서 트래픽의 최대를 구하는 것이다. 처음에는 모든 트래픽에 대한 sss 배열을 만들어 겹치는 부분을 세서 최대가 되는 횟수를 반환할려고 했었다. 당연히 메모리 에러가 났다.
그러다가 결국 트래픽 최대 수가 바뀌는 지점은 로그가 시작할 때와 끝날 때이다. 따라서 각 로그에 대해서
- [로그 시작 -1 ~ 로그 시작]
- [로그 시작 ~ 로그 시작+1]
- [로그 끝 -1 ~ 로그 끝]
- [로그 끝 ~ 로그 끝+1]
를 모두 각각 탐색한다면 모든 임의의 1초 경우를 셀 수 있다. 그렇기 때문에 각 로그에 대해 다른 로그가 포함되는 지 탐색해야하므로 O(n^2)의 시간 복잡도를 가진다. 계산의 편이를 위해 모두 초단위로 바꾸어주고 비교를 시작했다.
코드를 보자.
# 시간을 초단위로 변환
def get_time(time):
h, m, s = time.split(":")
return 2400*int(h)+60*int(m)+int(s[:2])+0.001*int(s[3:])
def solutions(lines):
answer = 0
n = len(lines)
# 시작, 끝 추출하기
intervals = []
for line in lines:
date, time, process = line.split(" ")
end_time = get_time(time)
start_time = end_time - float(process[-1:])
intervals.append([start_time, end_time])
# 각 로그 시작+-1, 끝 +-1에 대해 비교
for i in range(n):
current_start, current_end = intervals[i]
prev_start, after_start, prev_end, after_end = 1, 1, 1, 1
for j in range(n):
if i!=j:
# 비교 로그의 끝이 로그 시작보다 크고, 비교 로그의 시작이 로그 끝보다 작음
if intervals[j][0] < current_start and intervals[j][1] > current_start-1:
prev_start += 1
if intervals[j][0] > current_end and intervals[j][1] < current_end -1:
prev_end += 1
if intervals[j][0] < current_start+1 and intervals[j][1] > current_start:
after_start +=1
if intervals[j][0] < current_end+1 and intervals[j][1] > current_end:
after_end +=1
max_time = max([prev_start, after_start, prev_end, after_end])
if max_time > answer:
answer = max_time
return answer
Leave a comment